
Highlights
- Google launched Gemini 3.1 Flash-Lite, its most budget-friendly and quickest AI model.
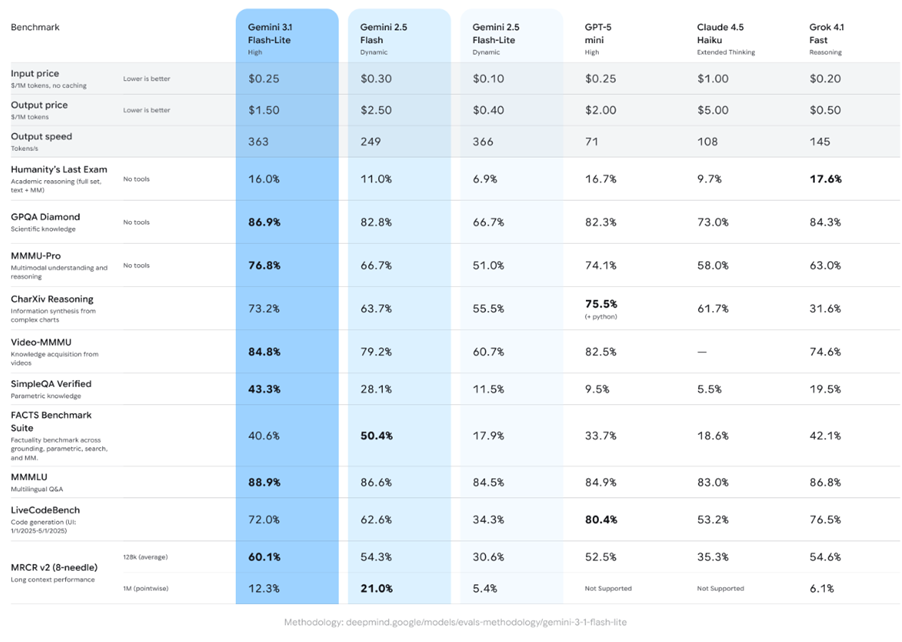
- It is priced at $0.25 per million input tokens and $1.50 per million output tokens.
- The model delivers 2.5X faster time-to-first-token and 45% faster output speeds with enhanced reasoning and multimodal capabilities.

Google Unveils Gemini 3.1 Flash-Lite. (Image credit – Google)
Google has introduced Gemini 3.1 Flash-Lite, its newest lightweight AI model designed to deliver faster performance at a significantly lower cost. Positioned as the most affordable and quickest option in the Gemini 3 series, the model targets developers handling high-volume workloads who need rapid responses without stretching budgets.
Gemini 3.1 Flash-Lite is currently available in preview through the Gemini API in AI Studio and for enterprise users via Vertex AI.
Built for High-Volume Developer Workloads
In a post on its Keyword blog, Google detailed how Gemini 3.1 Flash-Lite is optimised for developers managing large-scale operations. The company describes it as the ideal solution for those working with “high-volume workloads.”
Similar to Google’s earlier cost-efficient AI models, Gemini 3.1 Flash-Lite comes with competitive pricing. It is offered at $0.25 per one million input tokens and $1.50 per one million output tokens, making it one of the most affordable models in its class.
Performance Improvements Over Gemini 2.5 Flash
Beyond pricing, Google emphasised the performance gains compared to its predecessor, Gemini 2.5 Flash. According to the company, the new 3.1 Flash-Lite model delivers “2.5X faster Time to First Answer Token.” In addition, output speed has improved by 45 percent.
On the Arena.ai Leaderboard, Gemini 3.1 Flash-Lite achieved a score of 1,432, further underlining its competitive standing among lightweight AI models.
Enhanced Reasoning and Multimodal Capabilities
Google states that Gemini 3.1 Flash-Lite can “outperform” competing models in reasoning and multimodal understanding benchmarks including its own 2.5 Flash model. The AI offers developers flexibility in adjusting how it “thinks,” enabling fine-tuned control based on workload demands.
For more complex tasks, the company says the model supports “in-depth reasoning,” allowing it to generate user interfaces, build simulations and accurately follow detailed developer instructions. This scalability makes it suitable for both simple and advanced use cases.
Early Testing and Availability
Several companies including Latitude, Cartwheel, and Whering, have reportedly tested Gemini 3.1 Flash-Lite via AI Studio and Vertex AI with initial feedback described as positive.
Developers can begin testing Gemini 3.1 Flash-Lite starting March 3, 2026. Google confirmed that the model is available in preview through the Gemini API in AI Studio as well as on Vertex AI for enterprise customers.
With faster response times, improved output speeds, and aggressive pricing, Gemini 3.1 Flash-Lite aims to strengthen Google’s position in the competitive AI development space.
FAQs
Q1. What is Gemini 3.1 Flash-Lite and who is it designed for?
Answer. Gemini 3.1 Flash-Lite is Google’s newest lightweight AI model, built to deliver faster performance at lower costs. It is designed for developers managing high-volume workloads who need rapid responses without exceeding budget limits.
Q2. How does Gemini 3.1 Flash-Lite improve on Gemini 2.5 Flash?
Answer. The model offers 2.5X faster time-to-first-token and 45% faster output speeds compared to Gemini 2.5 Flash. It also enhances reasoning and multimodal capabilities, outperforming competitors in benchmarks.
Q3. Where can developers access Gemini 3.1 Flash-Lite and what is its pricing?
Answer. Developers can test the model in preview via the Gemini API in AI Studio and enterprise users can access it through Vertex AI. Pricing is set at $0.25 per million input tokens and $1.50 per million output tokens, making it one of the most affordable options available.






{kind=link}